")
With 43.6% sites built on WordPress, you’d think migrating content into it would be simple. It’s not. Especially not, when the source site runs on an older CMS or a custom-coded site or site built on other platforms and languages such as Magento, .net, etc.
In those cases, migration doesn’t remain about porting content. It becomes the case of preserving URLs, avoiding SEO disasters, re-mapping content structures, and rewriting everything from embedded media links to legacy styles. There have been instances of up to 55% traffic drop post migration.
Manual migration works if you have few minimum styling pages and unlimited patience.
But for migrating large websites having hundreds-or thousands of content blocks that need to fit cleanly into WordPress’s ACF( Advanced Custom Field) Flexible layouts?
Manual content extraction is something we never recommend as a primary approach. It’s difficult, demanding, and with no finish line in sight. Error-prone and unscalable, go without saying.
At Mavlers, our point of view is clear:
Done-right web scraping is one of the scalable content migration methods that works for ACF-based WordPress.
We’ve been building on WordPress for over 13 years. It has taught us a great deal about the right process and the right tools for content scraping for WordPress migration.
In our latest project, we automated the entire content migration using smart web scraping, PHP scripts, and the WP All Import plugin. Everything tailored to work seamlessly with ACF’s flexible content structure.
If you’re planning a web scraping–based migration, this post is your roadmap. It walks you through how we pulled it off: from sitemap extraction to ACF-compatible CSV structuring, step-by-step.
Step-by-step process: web scraping for content migration to WordPress (ACF flexible content structure)
For those of you who are not done weighing the pros and cons of a WordPress migration, this comprehensive guide on Why and How to Move Your Website to WordPress the Right Way will help you through the foundational decisions.
But if you’re already past that stage and staring at hundreds of structured content blocks, here’s how we pulled off a clean, scalable migration to WordPress site built with ACF flexible content.
For context— ACF (Advanced Custom Fields) is one of the most trusted plugins among WordPress developers. It adds over 30 types of custom fields to help structure your content better. With ACF’s Flexible Content field feature you have power to build dynamic, modular page layouts.
Step 1: Extract URLs with Screaming Frog SEO Spider
The first step in the process of web scraping for content migration is to scan the entire old website and collect every URL you want to move. The aim is to identify what content to scrape.
For this, our team used Screaming Frog SEO Spider to crawl the legacy website and extract all the URLs needed for WordPress content migration.
The tool:
- Crawls the site automatically.
- Saves these URLs in a simple CSV file (like an Excel spreadsheet).
- Filters URLs if you want only a certain page type.
This step paints a clear scope of content pages you should target for scraping.
Step 2: Scrape target content from each URL with a PHP script
Next, you create a PHP script to loop through each URL and extract only the content required.
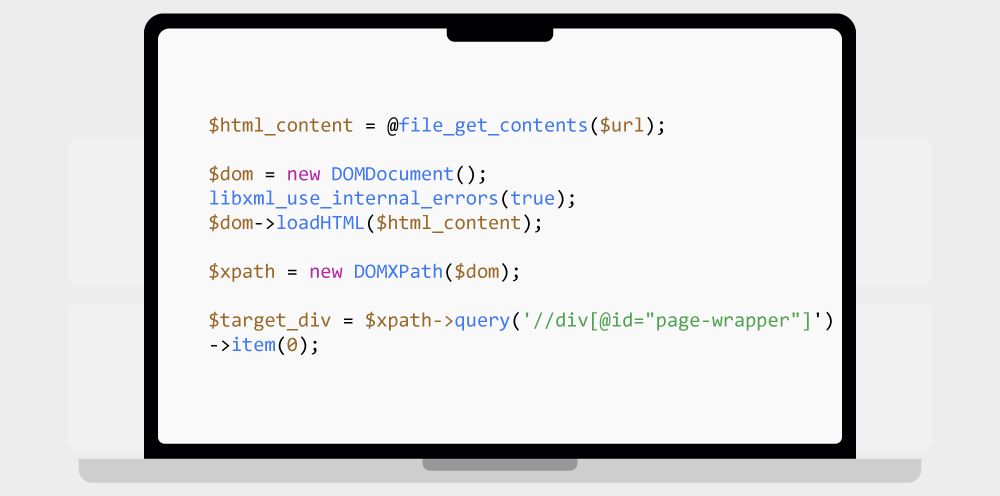
It looks inside the page for the specific part that contains your main content (in this case, the <div> with ID “page-wrapper”).
This gets only the useful content, not the whole webpage code, so it’s easier to work with later.
Code Snippet: Scraping Script
$html_content = @file_get_contents($url);
$dom = new DOMDocument();
libxml_use_internal_errors(true);
$dom->loadHTML($html_content);
$xpath = new DOMXPath($dom);
$target_div = $xpath->query('//div[@id="page-wrapper"]')->item(0);
This PHP script:
- Reads each URL from the input CSV, preparing to fetch the content from those web pages.
- Fetches the webpage’s HTML content. For each URL, the script sends a request to the website and downloads the HTML code of that page.
- Parses it into a DOM (Document Object Model) tree. Raw HTML is more of a long, chunky text. The script turns this text into a structured “tree”. Wherein each element represents a node in the tree. The structured representation is useful for the script to find the exact content it needs inside the webpage.
- Extracts relevant HTML inside the target div. With the DOM tree, the script finds this specific div element and extracts only the HTML contained inside it.
- Writes to a new output.csv file. The script saves the content extracts in a new CSV file.
Output: output.csv containing url, raw HTML content
Step 3: Split and structure content for ACF flexible layouts
Raw HTML is messy and hard to use as it is. That is because it’s not without unwanted code, broken characters, inline styles, or tags that do not necessarily fit your new site’s design or structure.
Plus, straight up importing this “raw” data would lead to badly formatted pages, broken layouts, or garbled text on your new WordPress site.
Hence, the onus is on you to restructure it and match the WordPress backend layout.
So, you run another PHP script that transforms and cleans the content.
What this script does:
- Cleans broken encodings (’, £, etc.). It detects these malformed sequences in the text and replaces them with the correct characters.
- Extracts the text inside the <h1> titles and saves it to your dataset. This way it can be imported as the title field for each WordPress post or page.
- Pulls paragraphs from #content and other relevant containers while ignoring sidebars, footers, or unrelated parts.
- Parses the HTML, scans the content before the “More Inspiration” section, and collects image filenames (e.g., image1.jpg). These filenames will then be used during import to connect media files properly.
The script ignores any images after the “More Inspiration” block to avoid migrating unrelated or promotional images.
- Retrieves spec key/value pairs from custom classes. Spec key/value pairs are label-detail pairs like “Color: Red” on product pages. Custom classes help the script find these pairs.
The script extracts and organizes this info so it imports neatly into WordPress custom fields using ACF. This preserves the structure and the clarity of the data after migration.
- Organizes text-image modules for ACF fields. The step is essentially about grouping the extracted text paragraphs and images into separate “modules” or blocks, following the layout design of your WordPress site using ACF Flexible Content fields.
All this is to keep the content is easily editable and manageable once imported.
ACF Mapping Strategy
The final CSV is structured with columns like:
| id | url | title | content | full image 1 | specification key | specification value | … |
All formatted to be mapped in WP All Import to the relevant ACF field groups.
Output: Sheet1-split.csv with clean, structured content for import
Step 4: Upload media files to WordPress
Using the media filenames from the previous step, all relevant images are uploaded to your new WordPress site’s Media Library ahead of import.
This ensures that WP All Import could match image URLs correctly during the migration process.
Step 5: Import structured data with WP All Import
With the structured CSV and media files in place, the WP All Import plugin is used to bring everything into WordPress.
Here’s why this tool is ideal:
- Maps each CSV column to ACF fields. Meaning that, you can easily connect your imported data to the custom modular layouts built with ACF Flexible Content.
- Supports conditional rules and flexible layouts, so you can customize the import logic as suits your needs.
- Handles media mapping if filenames in your CSV match to those already uploaded in the WordPress Media Library.
We found that the flexibility WP All Import offered made the entire import pretty smooth and highly customizable.
Step 6: QA and final delivery
The last step post-import is to review the site was in a QA environment to make sure:
- Content formatting stays intact.
- Layouts match the flexible field structure.
- No data loss or display issues occur.
Once everything checks out in QA, the final build goes live after receiving client approval.
Lessons learned—and how to reuse this workflow
That’s how we now have a workflow that we can reuse and scale for sites with a similar structure. With a few tweaks, the same scraping-to-import pipeline can be reused across similar websites, especially those built on legacy CMSes with structured layouts.
Here’s what this project reinforced:
- Lock down your backend layout before you extract a single data point. Content structure should always follow the logic of your ACF flexible fields, not the other way around.
- Scrape responsibly. We throttle scraping (e.g. `sleep(1)`) to avoid getting blocked or frying someone’s server. It’s good manners and smart ops.
- Stage before pushing live. First try importing your content into a staging site, a safe, non-public version of your website, rather than directly on the live site that visitors see.
If it goes perfect on staging, repeat the import or migration on the live site confidently, minimizing downtime and errors.
- Automate the grunt work, inspect final results manually. Even with clean scripts and plugins, QA still still needs human eyes to catch what automation can’t.
This workflow gives us a scalable foundation for future WordPress content migrations and it’s battle-tested on real content.
The road ahead
If this guide helped you untangle the WordPress migration process with Web scraping, there’s more where that came from. You might want to check out:
- 10 Best WordPress Form Plugins (2025)
- The Complete Website Migration Checklist: A Comprehensive Guide to Seamless Transition and SEO Success
- Top 9 WordPress web development tools you can’t miss
Bookmark what you need and when your next migration project rolls in, you won’t be starting from scratch.
Rahul Kumar - Subject matter expert (SME)
With over 8 years of experience in the dynamic field of web development, he is currently rendering a lot of value as an SME at Mavlers, where he leads a team of ten talented members. His role involves project management, team leadership, and seamless client coordination to ensure the successful delivery of every project. His expertise encompasses front-end and back-end website development, blending technical skills with strategic insights to create robust and visually compelling websites.
Urja Patel - Content Writer
Urja Patel is a content writer at Mavlers who's been writing content professionally for five years. She's an Aquarius with an analyzer's brain and a dreamer's heart. She has this quirky reflex for fixing formatting mid-draft. When she's not crafting content, she's trying to read a book while her son narrates his own action movie beside her.
BA Tools So Good You’ll Rethink Documentation & Wireframing Forever
We Used AI For Project Management And These Tools Saved Us Hours Weekly